
Machine Learning-Driven Query Optimization: Automating and Enhancing Query Execution
The complexity of modern databases, combined with the ever-growing demand for faster data processing, poses significant challenges to query optimization.
Despite advancements in database systems, achieving optimal performance for all queries remains difficult due to the vast number of execution plans and underlying data distributions.
This project explores the integration of machine learning techniques into query optimization to automatically improve the execution of queries based on data patterns and workload characteristics.
The project focuses primarily on four key pillars.
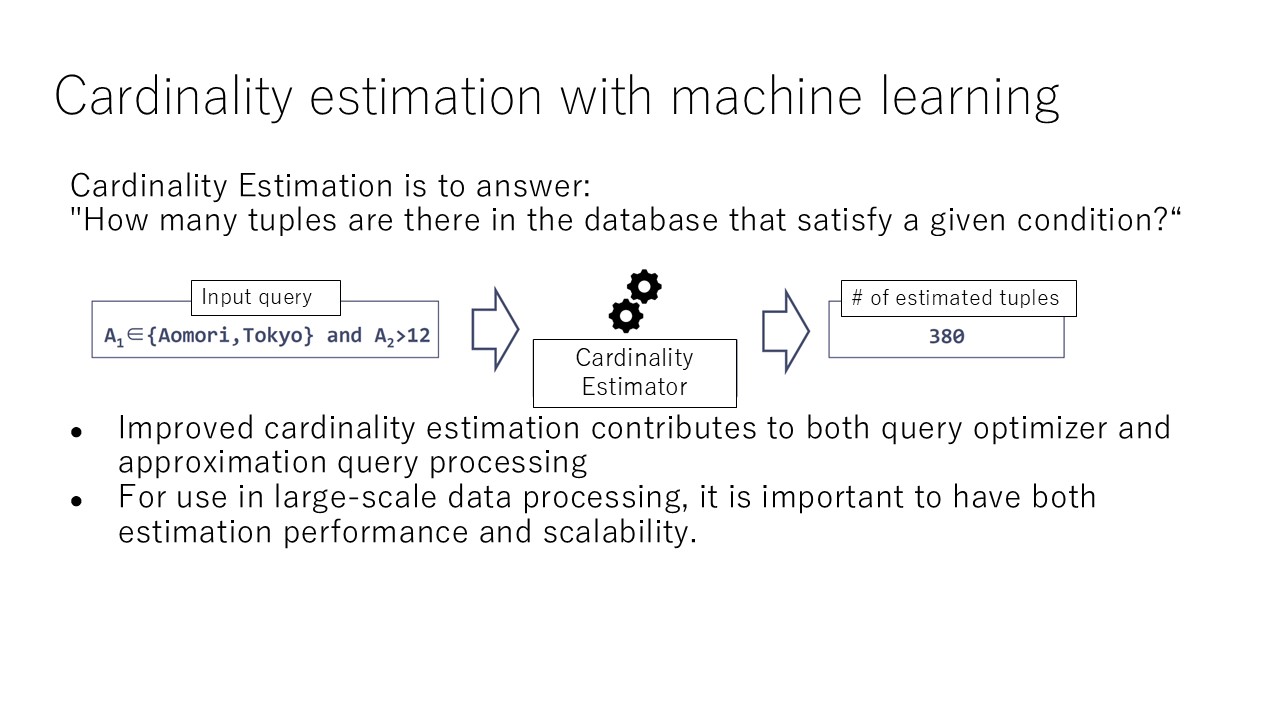
The first pillar tackles the acceleration of distributed join queries.
As part of this, we are developing techniques that use masked language models to learn dependencies between columns in a database, enabling cardinality estimation for partial queries [1], as well as techniques to simultaneously predict the fanout between records in order to apply cardinality estimation to join queries.
The second pillar focuses on deriving a series of materialized view changes that minimize execution costs for time-varying query workloads [2].
A key component of this work is formulating the schema optimization problem for time-varying workloads using linear integer programming.
Additionally, we are developing techniques to significantly reduce the number of candidate materialized views by creating and deleting them based on schema normalization and denormalization, capturing both global and local workload changes over time.
The final pillar involves optimizing cloud configurations for query workloads executed in cloud environments, with the goal of minimizing cloud costs while guaranteeing response times for each query.
In this pillar, we are collaborating with Treasure Data Inc., a company that provides data analytics services in the cloud, and are conducting research and development using real workloads.
Members
Publication list
[2] Yusuke Wakuta, Michael Mior, Teruyoshi Zenmyo, Yuya Sasaki, Makoto Onizuka: NoSQL Schema Design for Time-Dependent Workloads. CoRR abs/2303.16577 (2023)
[3] Taro L. Saito, Naoki Takezoe, Yukihiro Okada, Takako Shimamoto, Dongmin Yu, Suprith Chandrashekharachar, Kai Sasaki, Shohei Okumiya, Yan Wang, Takashi Kurihara, Ryu Kobayashi, Keisuke Suzuki, Zhenghong Yang, Makoto Onizuka: Journey of Migrating Millions of Queries on The Cloud. DBTest@SIGMOD 2022: 10-16
Funding
Resources
Distributed join query optimization using cardinality estimation: https://github.com/OnizukaLab/ScardinaPhoneBillsJoinEvaluation
Schema designer for time-dependent workloads: https://github.com/Y-Wakuta/nosql_time-series_schema_designer