
分散クエリ処理最適化
現代のデータベースの複雑さと、ますます高まる高速データ処理の需要が、クエリ最適化に重大な課題をもたらしています。
データベースシステムの進歩にもかかわらず、すべてのクエリに対して最適なパフォーマンスを達成することは、膨大な数の実行計画や基盤となるデータ分布のために依然として困難です。
本プロジェクトでは、クエリの実行をデータパターンやワークロード特性に基づいて自動的に改善するために、機械学習技術をクエリ最適化に統合することを探求します。
プロジェクトは主に4つの柱に焦点を当てています。
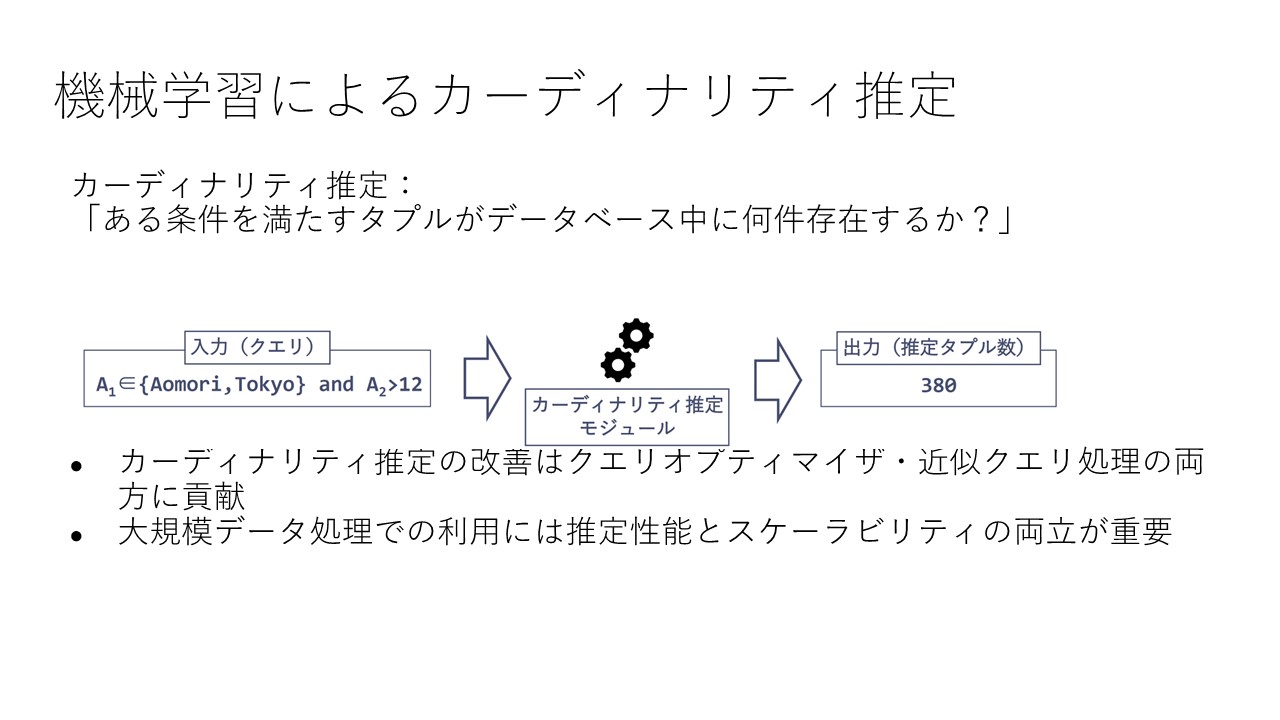
最初の柱では、分散ジョインクエリの高速化に取り組んでいます。
要素技術として、masked language model を用いてデータベースにおけるカラム間の依存関係を学習することで、部分クエリの cardinality estimationを行う技術 [1]、および cardinality estimation をジョインクエリに適用するためのレコード間の fanout を同時に予測する技術に取り組んでいます。
第2の柱では、時間変化するクエリワークロードに対して、ワークロードの実行コストを最小化する実体化ビューの変化系列を導出する研究に取り組んでいます [2]。
要素技術として、時間変化するワークロードに対するスキーマを最適化する問題を liner integer programing を用いて定式化し、更にスキーマの正規化・非正規化に基づいて実体化ビューの作成・削除し、時間軸方向で大域的なワークロード変化と局所的なワークロード変化を捉えることで、大幅に候補を削減する技術について取り組んでいます。
最後の柱では、クラウド環境で実行するクエリワークロードに対して、各クエリの応答時間を保証しながら、クラウドコストを最小化するクラウドコンフィグレーションの最適化の研究に取り組んでいます。
本柱では、クラウド上でデータ分析サービスを提供するTreasure Data Inc.社と協力して、実ワークロードを用いて研究開発に取り組んでいます。
Members
Publication list
[2] Yusuke Wakuta, Michael Mior, Teruyoshi Zenmyo, Yuya Sasaki, Makoto Onizuka: NoSQL Schema Design for Time-Dependent Workloads. CoRR abs/2303.16577 (2023)
[3] Taro L. Saito, Naoki Takezoe, Yukihiro Okada, Takako Shimamoto, Dongmin Yu, Suprith Chandrashekharachar, Kai Sasaki, Shohei Okumiya, Yan Wang, Takashi Kurihara, Ryu Kobayashi, Keisuke Suzuki, Zhenghong Yang, Makoto Onizuka: Journey of Migrating Millions of Queries on The Cloud. DBTest@SIGMOD 2022: 10-16
Funding
Resources
Distributed join query optimization using cardinality estimation: https://github.com/OnizukaLab/ScardinaPhoneBillsJoinEvaluation
Schema designer for time-dependent workloads: https://github.com/Y-Wakuta/nosql_time-series_schema_designer