Research
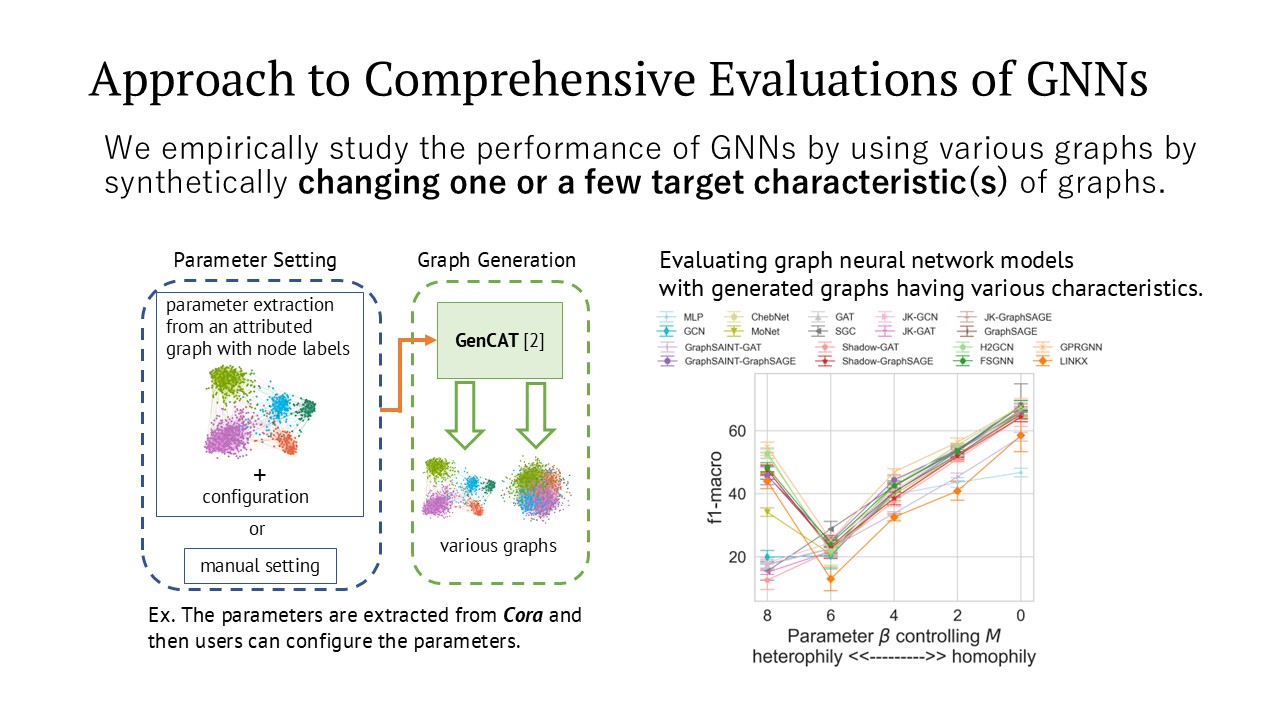
Large-Scale Graph Neural Networks
With the recent rise in machine learning, neural network is also applied to graph data, which has a more versatile data structure, has gained significant attention. This project is working on developing technologies to process graph deep learning with higher accuracy and speed, as well as creating benchmarks to evaluate the performance of various graph neural networks.
Graph Database Management Systems
Graph data can model various relationships between objects and has practical applications in everyday life. For instance, we can use knowledge graphs that structure relationships between objects for web search engines and recommendation systems. Additionally, molecular data can be represented by atoms as objects and the bonds between atoms as relationships, enabling searches for molecules with the same data structure. Social networking services and road networks are also closely related to our daily lives. The scale and diversity of graph data are continuously expanding.
There is a growing demand for database technologies that enable efficient management and fast searching of large-scale and diverse graph data. In industries, graph database systems are among the most highly anticipated database systems, with major companies such as Amazon, Microsoft, and Google developing them. However, there is still significant room for further development.
Our research focuses on fundamental technologies for graph database management and aims to develop a new database management system. For example, we explore indexing and query optimization techniques to accelerate graph data queries, as well as the use of machine learning to speed up searches. In addition, we contribute graph database scandalizations.

Optimizations for Large Language Models: Developing core technologies for enhancing the capabilities of large language models
Large language models (LLMs) are designed to handle and produce extensive natural language content. They develop an understanding of the structure, meaning, and knowledge embedded in human language datasets. Our focus includes three specific areas: (1) Fundamental technologies in Transformer-based LLMs, (2) Tailoring LLMs to specialized tasks, and (3) Refining methods for LLM agents.

Smart Agent-Based Modeling: Leveraging foundation models for agent-based modeling
Smart agents are intelligent, adaptive, and computational entities. While humans are the canonical smart agents, the advent of foundation models - imbued with remarkable language, vision, and reasoning abilities that emulate human behavior - enables us to expand the concept of smart agents to agent-based modeling (ABM). This evolution leads to the introduction of smart agent-based modeling (SABM). Unlike traditional ABM, SABM incorporates foundation models as agents and formulates models using natural language. We employ SABM to investigate natural processes across various fields such as economics and behavioral science. We believe that SABM offers a more nuanced and realistic approach to enhancing our comprehension of natural systems.
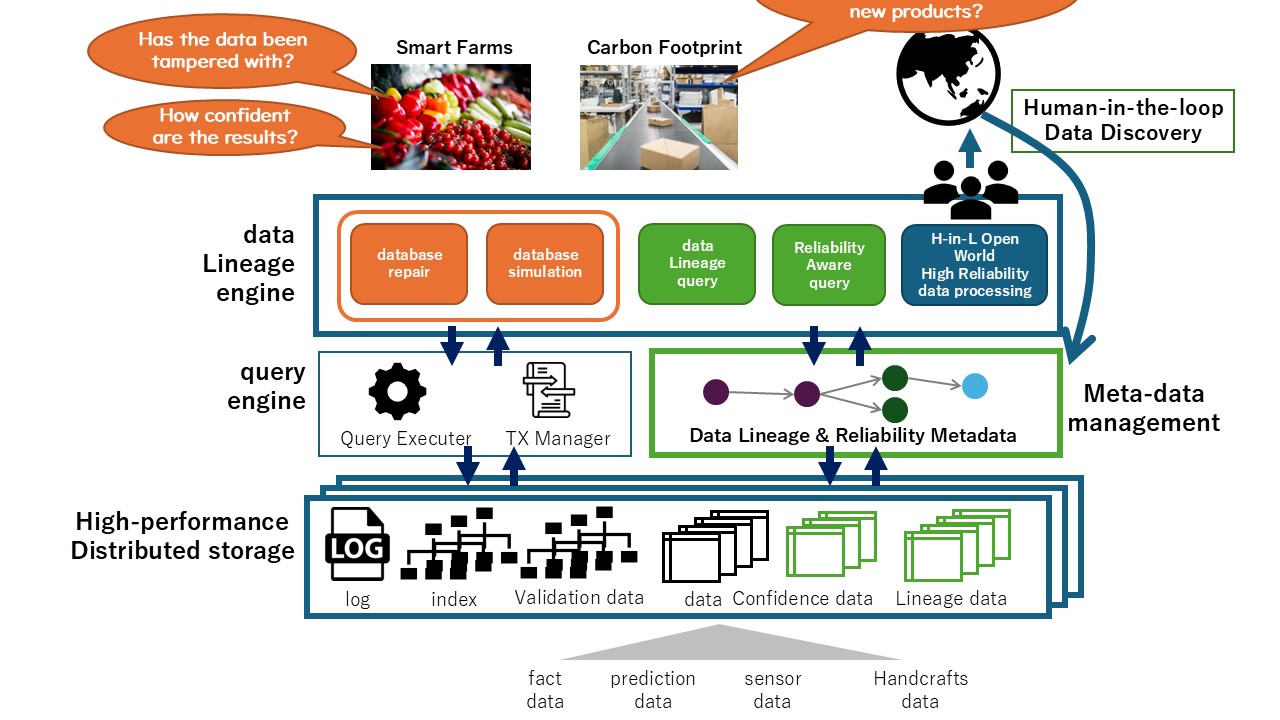
Verifiable Data Ecosystem
We research and develop a verifiable data ecosystem that supports the reliability and lineage of data as first-class data, enabling the validation of any data. We establish a theoretical foundation for a comprehensive reliability and validation model, as well as for database repair considering transaction histories. Furthermore, we investigate the system architecture, including highly reliable distributed storage, and conduct empirical experiments with prototype systems, and verify the effectiveness of the proposed systems.
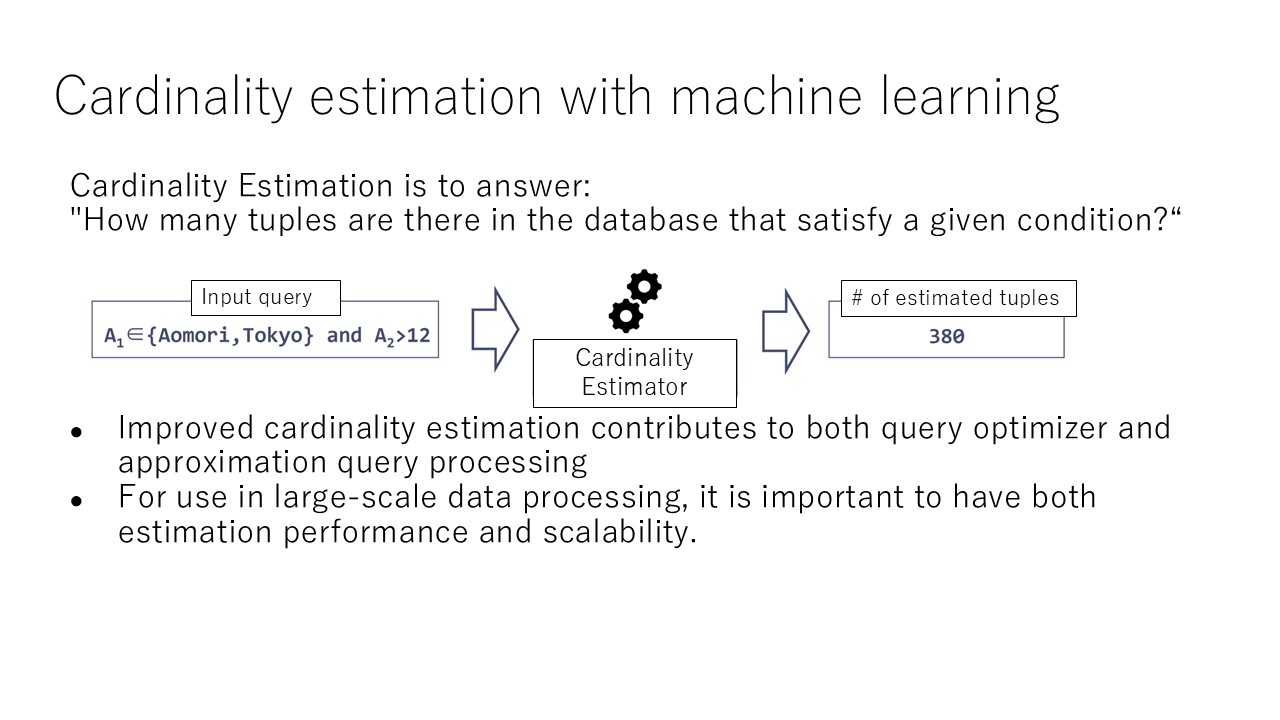
Machine Learning-Driven Query Optimization
The complexity of modern databases, combined with the ever-growing demand for faster data processing, poses significant challenges to query optimization. Despite advancements in database systems, achieving optimal performance for all queries remains difficult due to the vast number of execution plans and underlying data distributions. This project explores the integration of machine learning techniques into query optimization to automatically improve the execution of queries based on data patterns and workload characteristics.
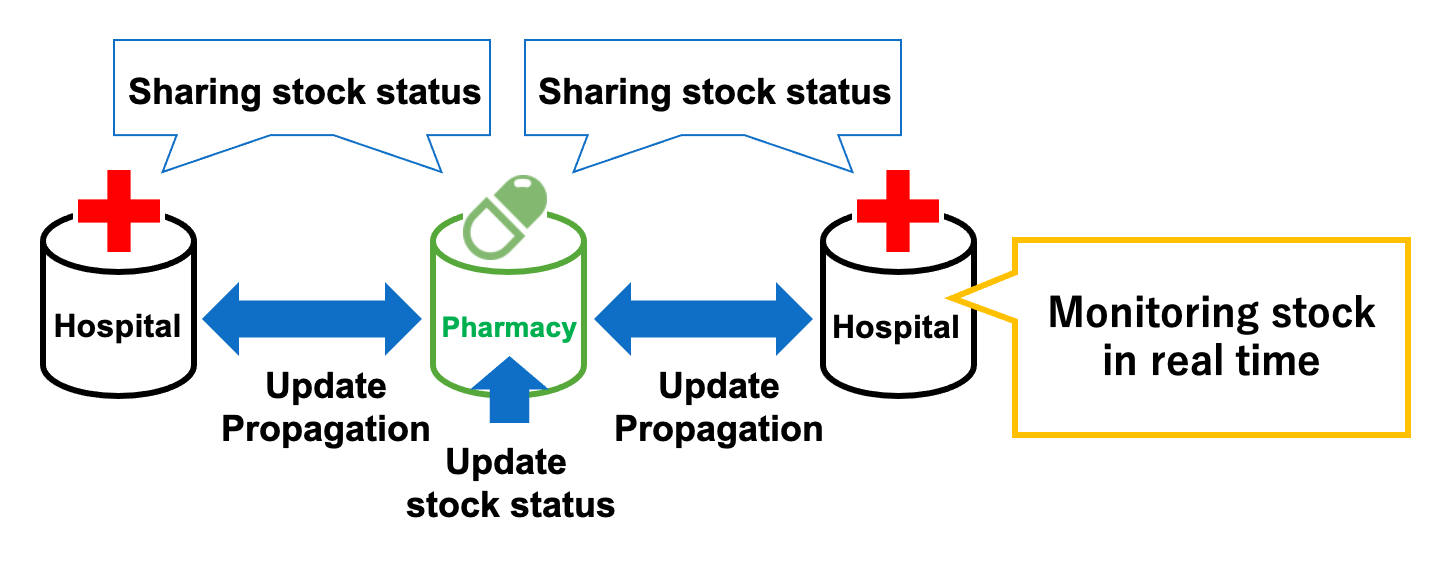
Data Integration
Data integration is the process of providing the user a unified view of data residing at different databases. Recently, as the amount of generated data has been increasing, the demand for utilizing distributed data as a whole also has been increasing. We are researching efficient transaction management method in the P2P-based data integration architecture, called Dejima.
Past Research
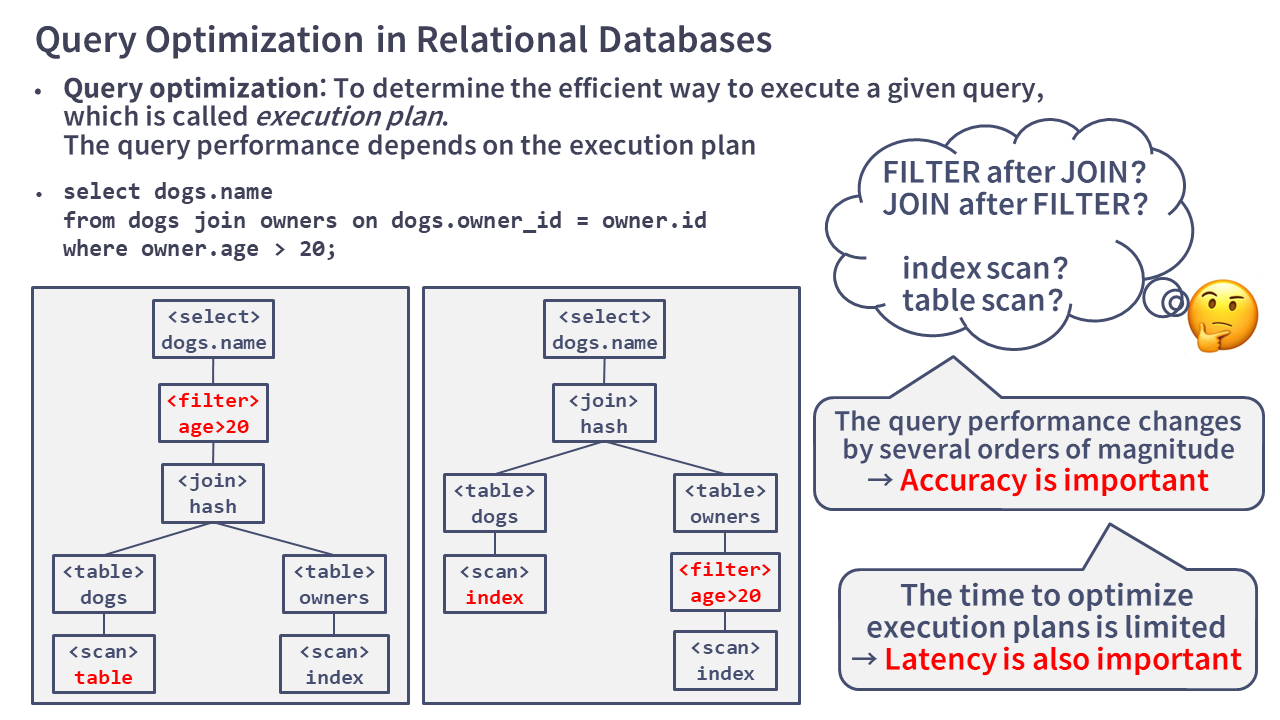
Query Optimization
In recent years, machine learning R&D and large-scale service development have become more popular. Therefore it is necessary to handle large amounts of data. In order to handle large-scale data efficiently, it is essential to accelerate database systems. We are working on accelerating database systems by obtaining efficient query plans with the following two approaches.
1. Using machine learning to capture data and workload characteristics
2. Formulating data storage and query as an optimization problem

Conversational Agents
We are studying conversation systems, in particular, systems for chit-chats. Our goal is to establish a conversation system with human-level communication skills such that it understands users’ language and emotions and reacts appropriately. We employ various machine learning methods for generating natural responses: neural networks and pre-trained language models. We also work on creating corpora for training conversation systems by two approaches: web-crawling and automatic generation using paraphrasing technologies.
Alignment-based semantic similarity assessment
Paraphrases convey the equivalent information in different expressions. Let’s take a pair of paraphrases: “The discussion heated up.” and “Their debate entered high gear.” as an example. Why we can understand they deliver the same information, even though they use totally different words? How our brains represent these expressions to estimate their semantic relevance? Paraphrases are the key to answer these questions. Paraphrases are also useful resources for applications that need to understand users’ saying, such as question answering and conversational agents. We are working on analysis of linguistic phenomena on paraphrases, as well as technologies to detect paraphrases. For more details, please visit our project web site.

Language Learning Support
We are developing assistive technologies for English education. Data-Driven Learning (DDL) is a trend in language education where students autonomously learn how a term and phrase is typically used through observing its use in various contexts. We are developing technologies to support DDL in collaboration with language education experts, for example, automatic assessment of sentence difficulty levels and automatic paraphrasing to control difficulty levels.
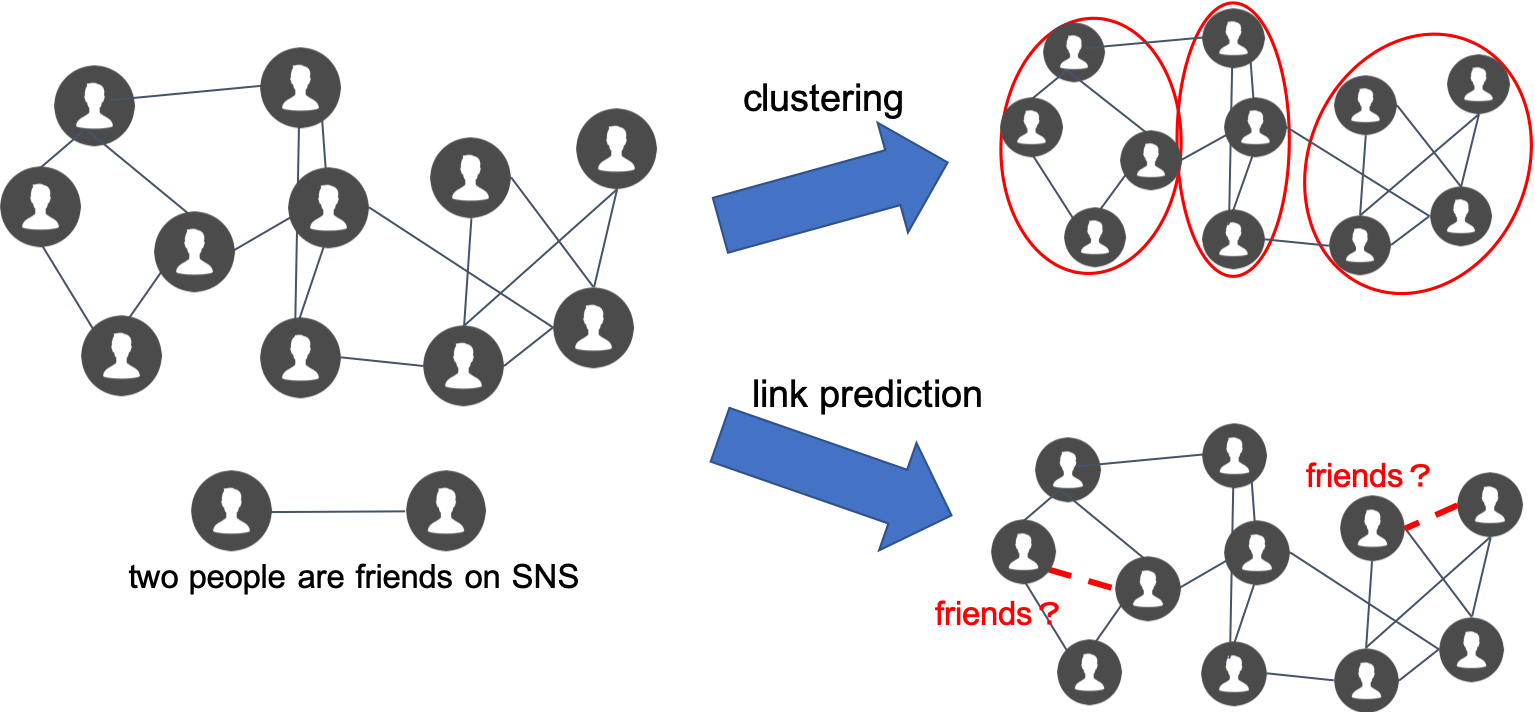
Graph Mining
Thanks to SNS, people have been more connected with each other than ever before, and many devices are likewise connected with each other via IoT technology. Graph data can represent these connections, so graph analysis attracts considerable attention. The goal of graph mining is to discover valuable insights from graph data. For example, clustering identifies groups where people (or devices) behave similarly. Another example is link prediction, which finds pairs of people (or devices) that are likely to connect with each other. These analytics are used for recommendation systems, marketing, and more, and so are employed in a wide variety of applications. We aim to develop efficient, effective graph mining methods.
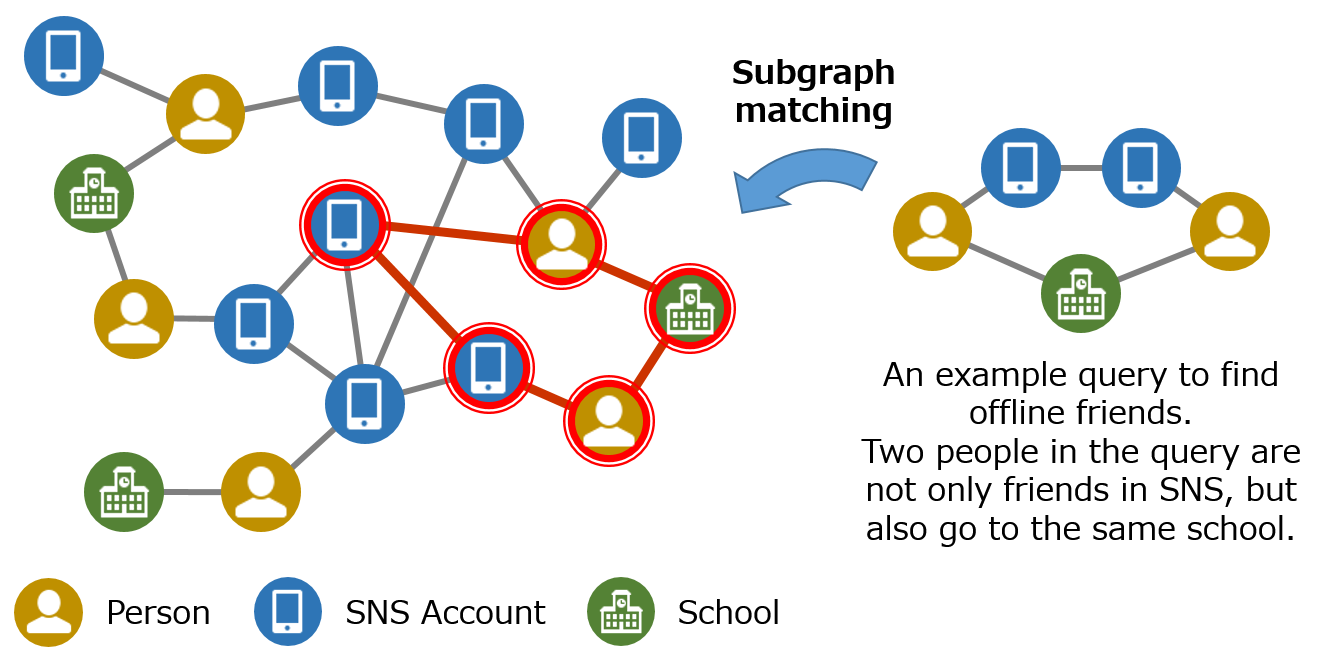
Subgraph Matching
The problem of searching for specific graph structures within a large graph is known as subgraph matching, and it is used to extract complex information from graphs. For example, in social networks, it can help identify individuals who are likely to be friends not only on social media but also offline. It can also be applied to detect accounting fraud, such as circular transactions, by analyzing graphs that represent business relationships between companies. Despite its many applications, subgraph matching is also known as an NP-complete problem, meaning that the processing time can increase explosively. Therefore, the Big Data Engineering Laboratory aims to develop algorithms that enable fast subgraph matching through efficient search methods.
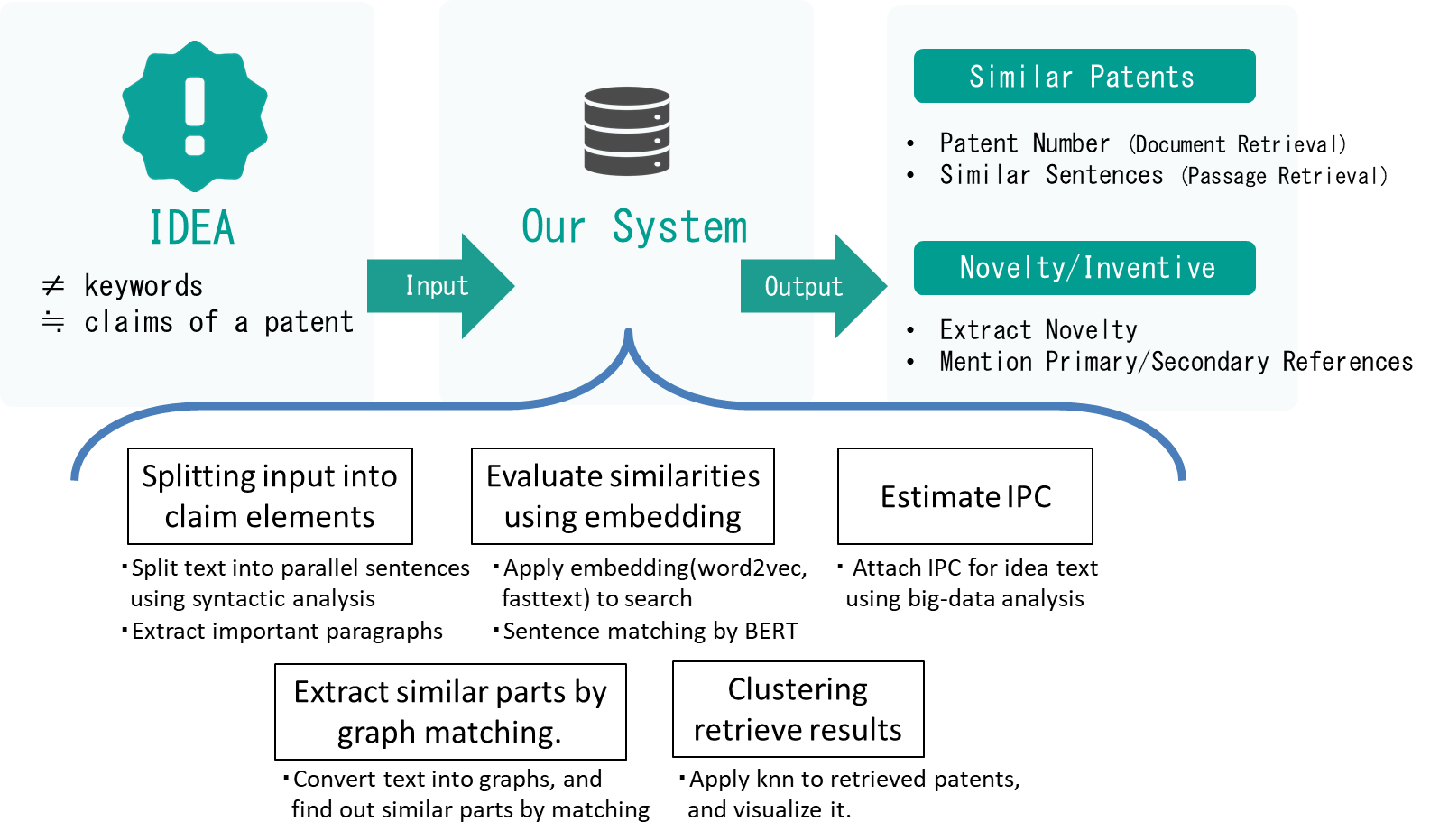
Patent Evaluating AI System
The number of registered patents in the world exceeds 10 million, and the number of patent applications per year exceeds 3 million. Thus, the burden of patent search on companies is increasing because of increasing of patents. In addition, the number of patent applications per year in China is much increasing and it is at the top of the world. The globalization of intellectual property rights is progressing, so it becomes more difficult to execute comprehensive patent search. In this research, we aim to develop a system for semi-automatic and highly accurate patent retrieval while utilizing the success of recent machine learning with neural network and incorporating big data analysis methods such as graph matching and clustering.
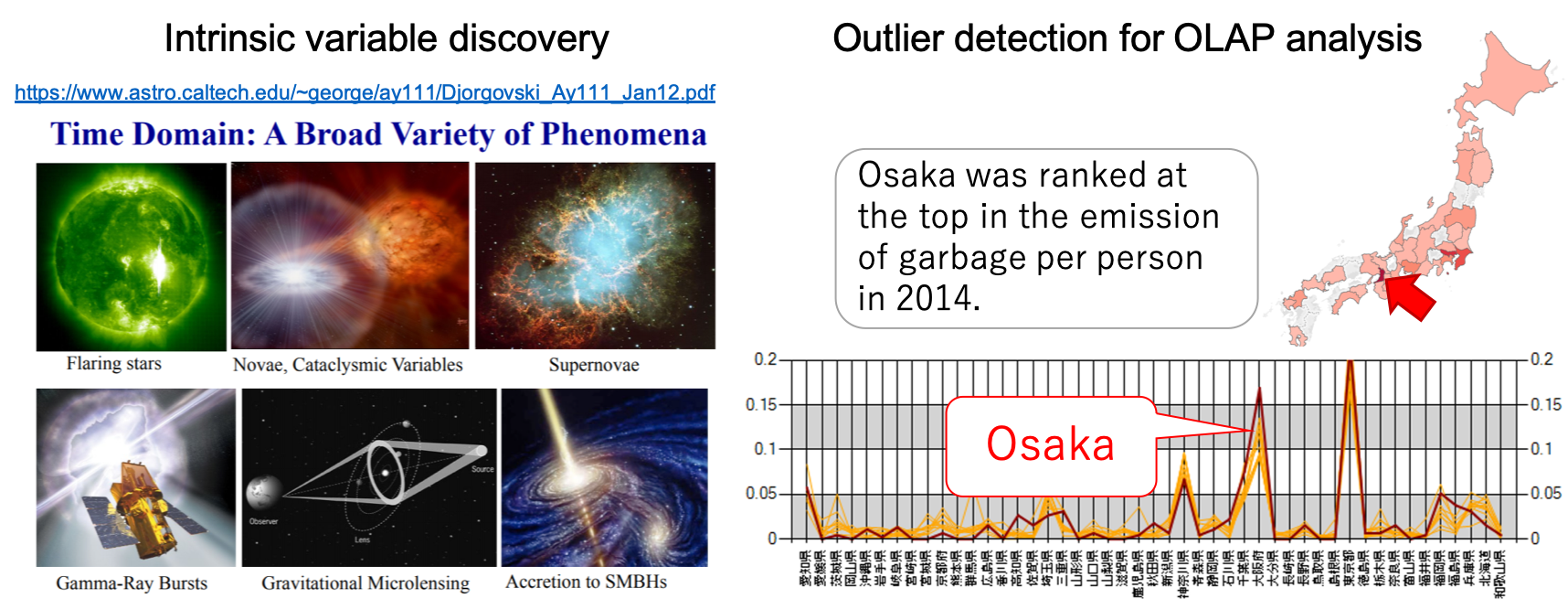
Exploratory Data Analysis
The exploratory data analysis is a technique for discovering characteristic data that largely differ from ordinary data, such as from purchase data and astronomical observation data. For example, we utilize important observations by discovering characteristic from the aspect of specific region or season. In particular, in collaboration with National Astronomical Observatory of Japan (NAOJ), we are working on the technology of outlier detection and imputation by learning normal patterns so that we aim to discover intrinsic variables whose brightness and position change in a short period of time.
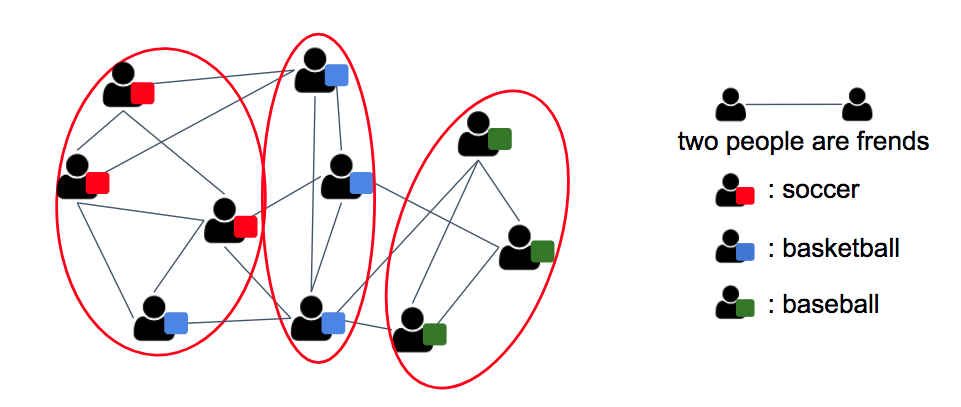
Attribute Graph Clustering
An attributed graph is a type of graph in which nodes not only have structural relationships defined by edges but also possess individual feature information. For example, in a social networking service (SNS), users can be represented as nodes, with edges indicating friendships between them, and features such as the user's interests or preferred categories serving as node attributes. One of the advantages of *attributed graph clustering* is that it can potentially produce better clusters by leveraging information that traditional methods often ignore.
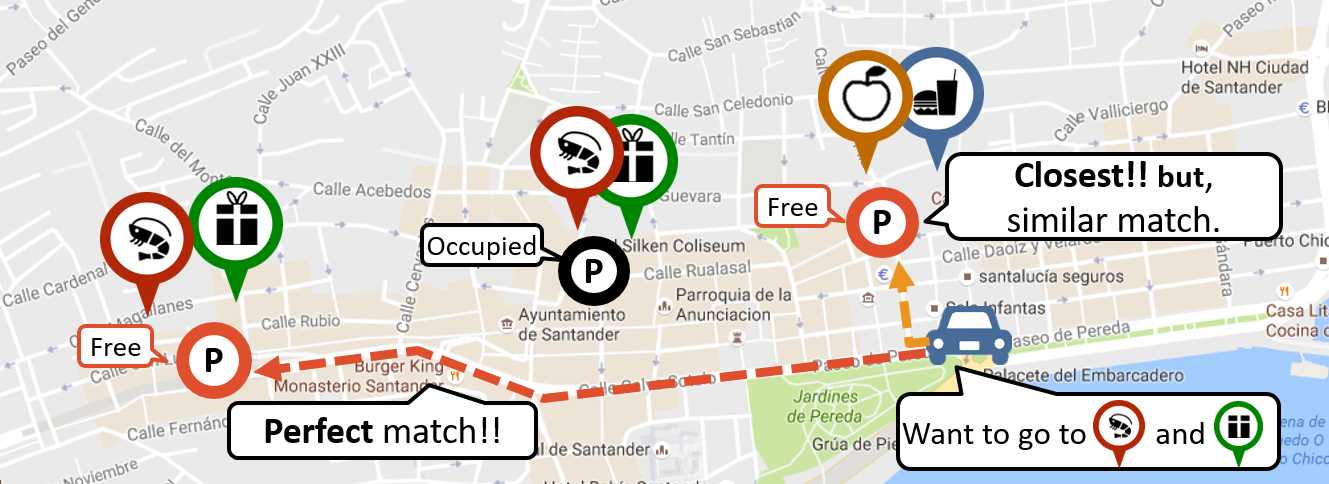
Route Search
We daily search routes from car navigation systems and smart phones. We propose new and useful types of route search that cannot be searched with existing services. In particular, we focus on actual attributes of data (e.g., category and text) and around information, for example we investigate routes with matching other attributes or integrating parking status. Besides this, we propose efficient algorithms of existing searches and implement services cooperating with local governments.
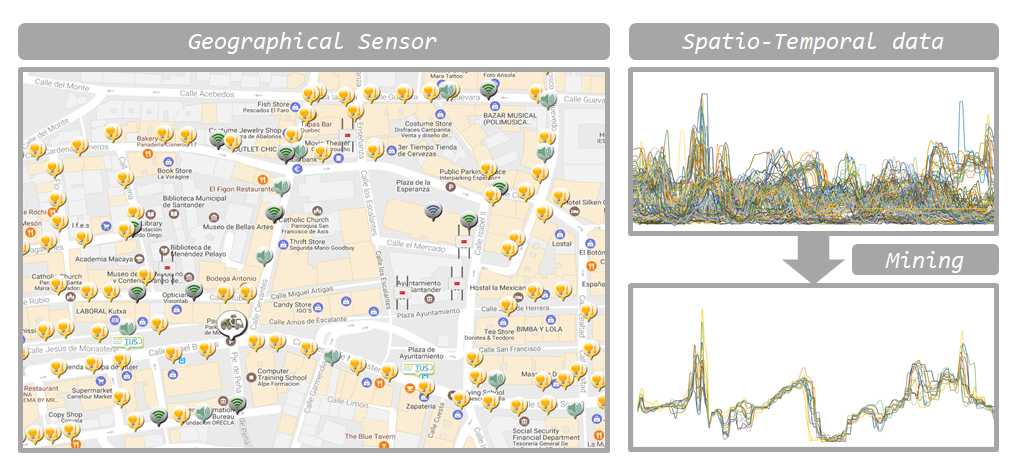
Spatio-temporal Data Mining
Local governments recently deploy many sensors in cities such as temperature, sound, traffic volume, and air pollution, and the sensors generate a large amount of data. We analyze the big data and obtain beneficial knowledges “temperature and traffic volume increase at the same time,” and “with increasing noise, air pollution also increases”. Our goal is to propose new techniques that find non-trivial knowledges.