
Verifiable Data Ecosystem
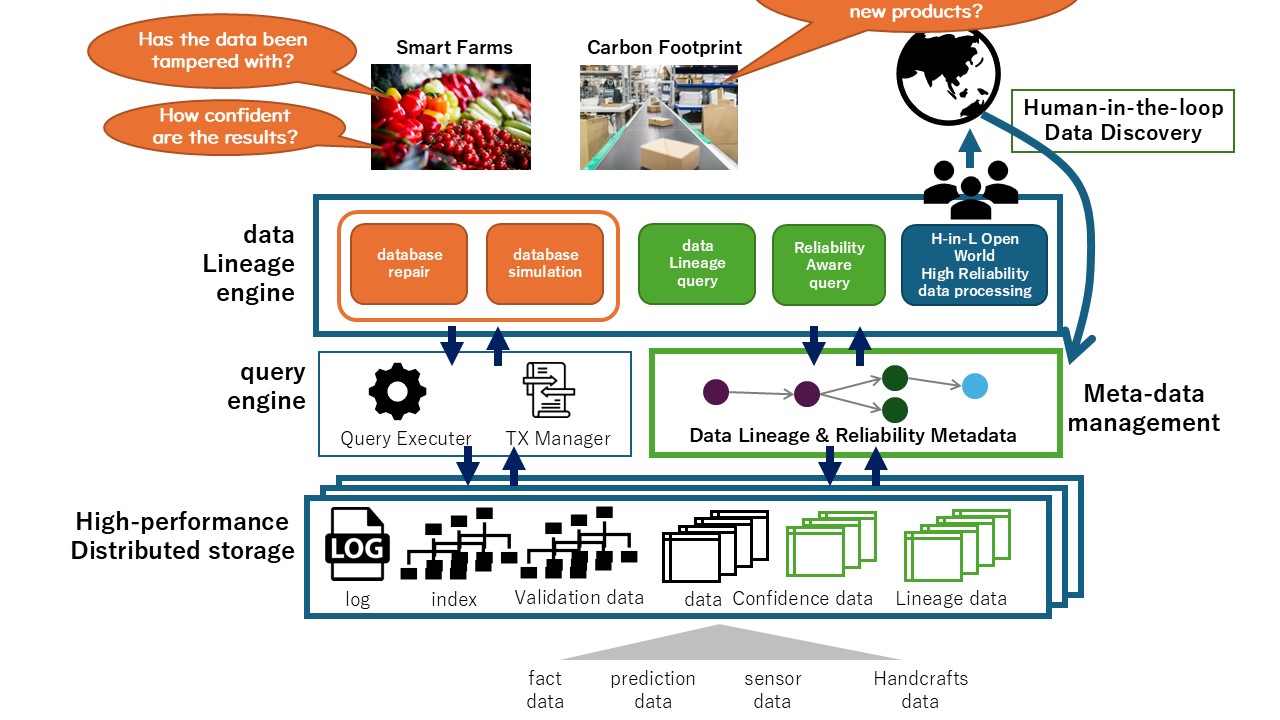
We research and develop a verifiable data ecosystem that supports the reliability and lineage of data as first-class data, enabling the validation of any data.
We establish a theoretical foundation for a comprehensive reliability and validation model, as well as for database repair considering transaction histories.
Furthermore, we investigate the system architecture, including highly reliable distributed storage, and conduct empirical experiments with prototype systems, and verify the effectiveness of the proposed systems.
This project is a collaborative effort among Tsukuba University, Nagoya University, Ochanomizu University, and Tokyo Institute of Technology. Osaka University focuses on three main topics.
The first topic involves implementing historical what-if query analysis by simulating the state of the database through partial modifications of transaction history [3].
Key technologies include an SQL transpiler that integrates application programs with SQL statements, and research into a DBMS plugin architecture that enables rapid re-execution of transactions after modifying past transactions.
The second topic focuses on data preprocessing (DP) [1, 3] using Bayesian models or large-scale language models. We select a collection of datasets across four representative DP tasks and construct instruction tuning data using data configuration, knowledge injection, and reasoning data distillation techniques tailored to DP.
Finally, research is being conducted on evaluating data providers, particularly in the context of machine learning. This includes studying the use of Shapley values for assessing the contribution of training data in horizontal and vertical federated learning environments.
Members
Publication list
[2] Yongrui Zhong, Yunqing Ge, Jianbin Qin, Shuyuan Zheng, Bo Tang, Yu-Xuan Qiu, Rui Mao, Ye Yuan, Makoto Onizuka, Chuan Xiao: Privacy-Enhanced Database Synthesis for Benchmark Publishing. CoRR abs/2405.01312 (2024)
[3] Haochen Zhang, Yuyang Dong, Chuan Xiao, Masafumi Oyamada: Jellyfish: A Large Language Model for Data Preprocessing. CoRR abs/2312.01678 (2023)
[4] Ronny Ko, Chuan Xiao, Makoto Onizuka, Yihe Huang, Zhiqiang Lin: Ultraverse: Efficient Retroactive Operation for Attack Recovery in Database Systems and Web Frameworks. CoRR abs/2211.05327 (2022)
Funding
Resources
Source code
Privbench (Privacy-Enhanced Database Synthesis for Benchmark Publishing): https://github.com/dsegszu/privbench
Jellyfish: https://huggingface.co/NECOUDBFM/Jellyfish-8B