
クエリ最適化
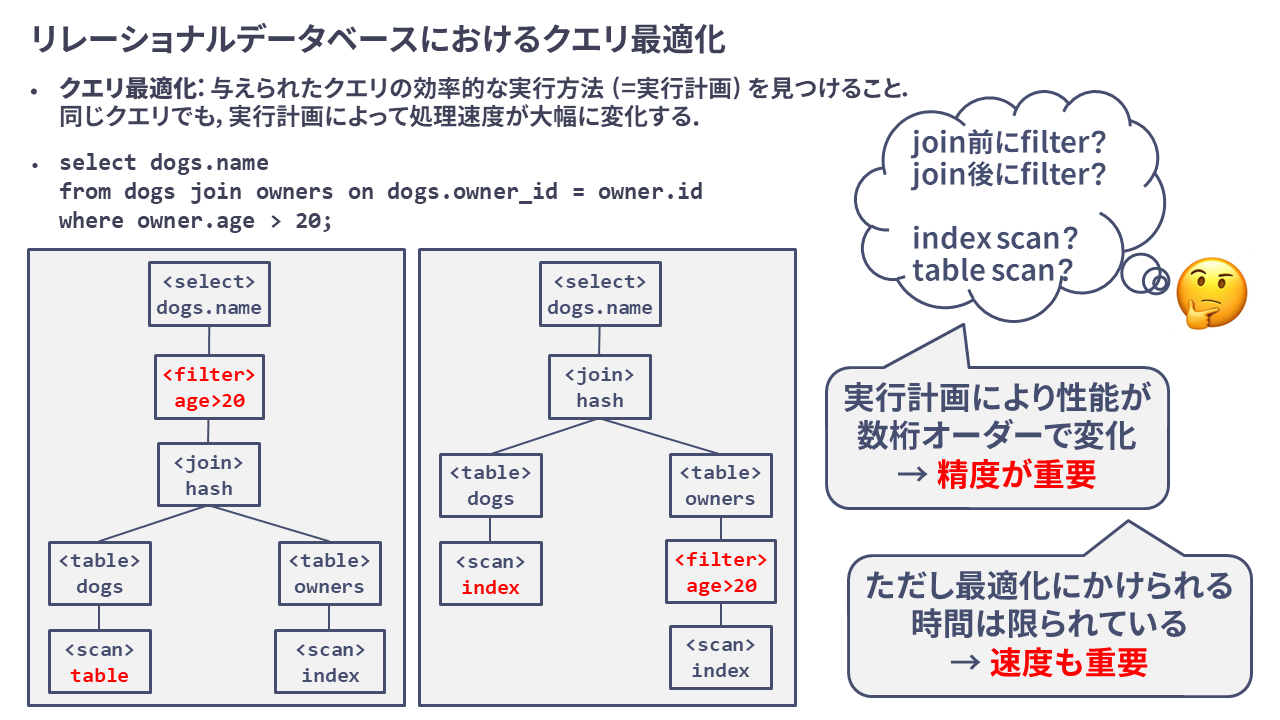
近年盛んな機械学習を用いた研究開発や大規模なサービス開発では大量のデータを扱う必要があります.そして,大規模なデータを効率的に扱うためにはその保管場所であるデータベースの高速化が欠かせません. 弊研究室では,以下の2つのアプローチでデータベース高速化に取り組んでいます.
- 機械学習を用いてデータやワークロードの特性を捉え,高効率なクエリの実行計画を得る研究
- データの保存方法やクエリの実行計画を最適化問題として定式化し,高効率なクエリの実行計画を得る研究
データ統合システム
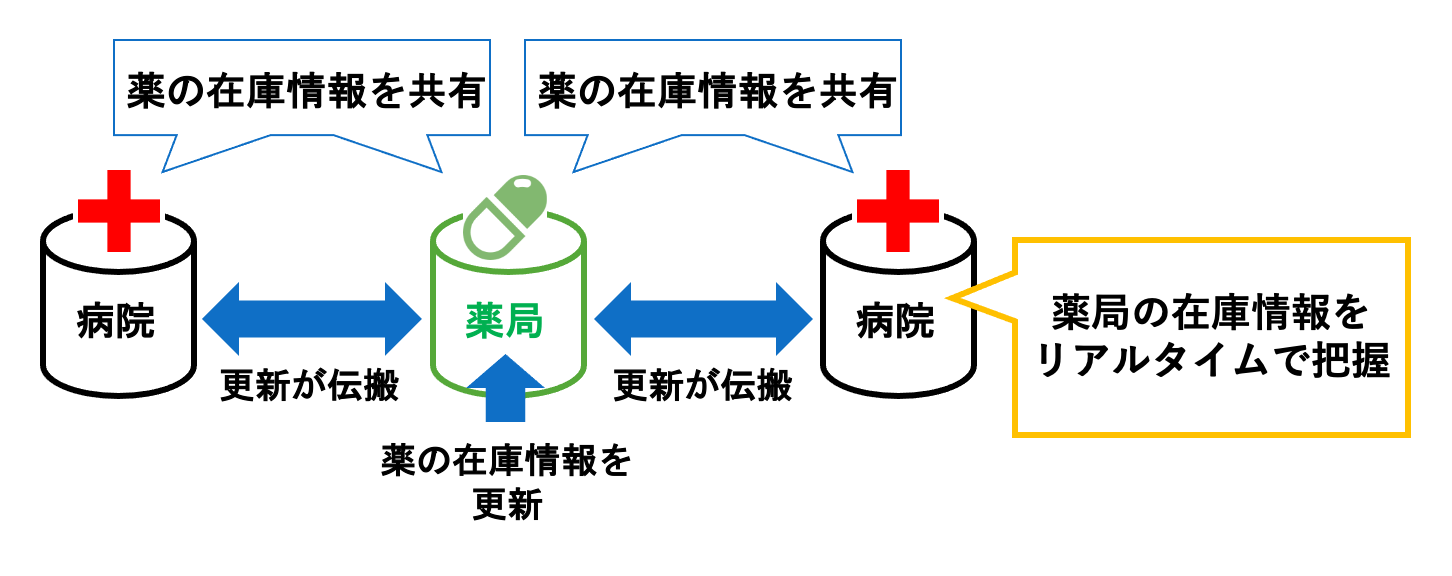
データ統合とは,複数のデータベースに分散する関連したデータを統合し,利活用を簡単にする技術です. 近年,生成されるデータ量は増大しており,複数のデータベースに蓄積されたデータの包括的な利活用に対し需要が高まっています. 本研究室では P2P ベースのデータ統合アーキテクチャにおける効率的なトランザクションマネジメント手法を研究しています.
対話システム

言葉を理解し,気持ちを察し,人間のような会話をする対話システムの実現を目指し,研究に取り組んでいます. 特に日常会話をするチャットボットと呼ばれるサービスを研究対象としています. 当講座では事前学習済み言語モデルを用いた生成ベースのアプローチを研究しています. 本研究はLINE社との共同研究の一環として,深層学習をはじめ様々な機械学習の手法を用い,自然で流暢な会話を生成する手法を開発しています. また,対話システムを構築する際には大量の会話データが必要となります. 当講座では,対話システム構築のためのデータの効率的な収集や自動生成にも取り組んでおります.
アラインメントに基づく意味の類似度推定
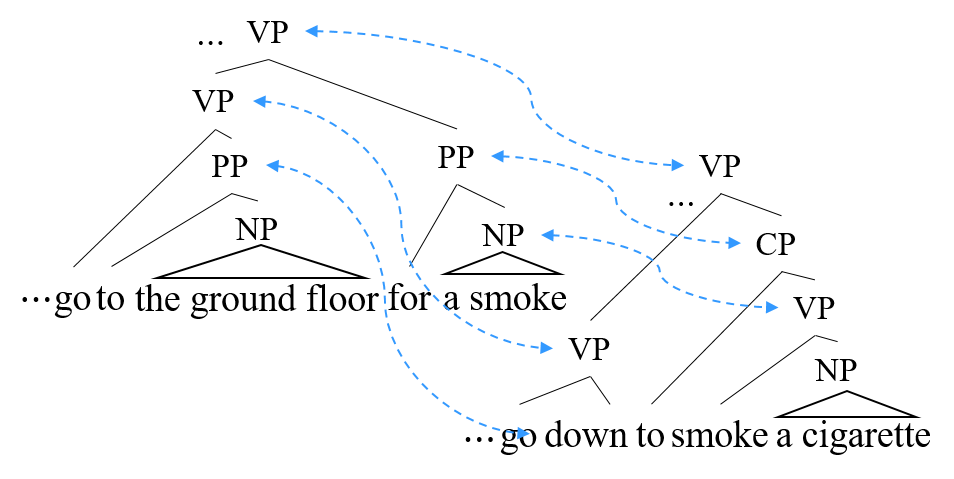
「The discussion heated up.」と「Their debate entered high gear.」のように, 同じ事象や概念を異なる表現でもって表したものをパラフレーズ(言い換え表現)といいます. この2つの文のように,まったく異なる単語から構成されるにも関わらず,なぜ人間はパラフレーズが同じ意味を表すと分かるのでしょうか? 人間の脳ではどのようにしてパラフレーズ,ひいては意味の表現を生み出しているのでしょうか? パラフレーズはこれらの謎を紐解く上で重要な手がかりです. また応用においても,人間の言語能力の推定や,自動質問応答,文書要約にも役立ちます. 私たちはパラフレーズに起こっている言語現象の分析,それを基にしたパラフレーズの認識技術の研究開発に取り組んでいます. プロジェクトページはこちら.
言語学習支援

言語学習支援では,英語を対象として学習者・教育者双方を支援する技術を研究しています. 英語教育では学習者自身が多量の用例を観察し,単語や句の用法を発見する自律的学習を行うData-Driven Learning (DDL) が注目されていますが,当講座ではDDLを促進するシステムを構築しています. 言語教育学の専門家と協力し,英文難易度の自動推定,英文難易度を自動的に調整する英文書き換え技術を開発しています.
グラフマイニング
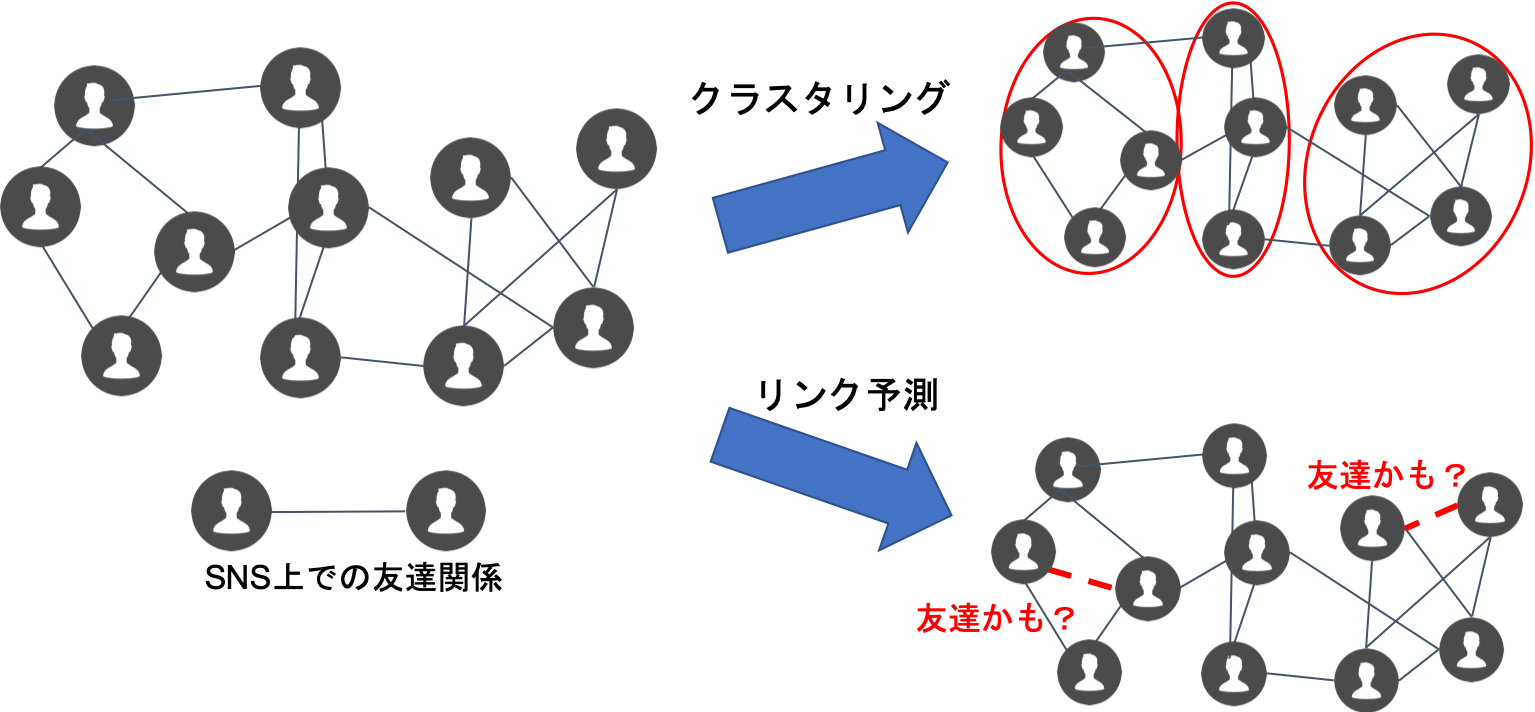
SNSによって人と人が繋がり,IoTによって機械と機械も繋がるようになり,それらの関係を表すグラフデータの解析が重要になってきています.グラフデータから有益な知見を見つけることを,グラフマイニングといいます(マイニング=採掘).具体的には,似た振る舞いをするグループ(コミュニティ)を見つけるクラスタリングや,次に繋がる可能性が高い箇所を見つけるリンク予測などが盛んに研究されています.このような分析はマーケティングや推薦システムに利用されており,実際のサービスでも広く活用されています.私たちは,より高精度でかつ高速な手法の開発を目指しています.
サブグラフマッチング
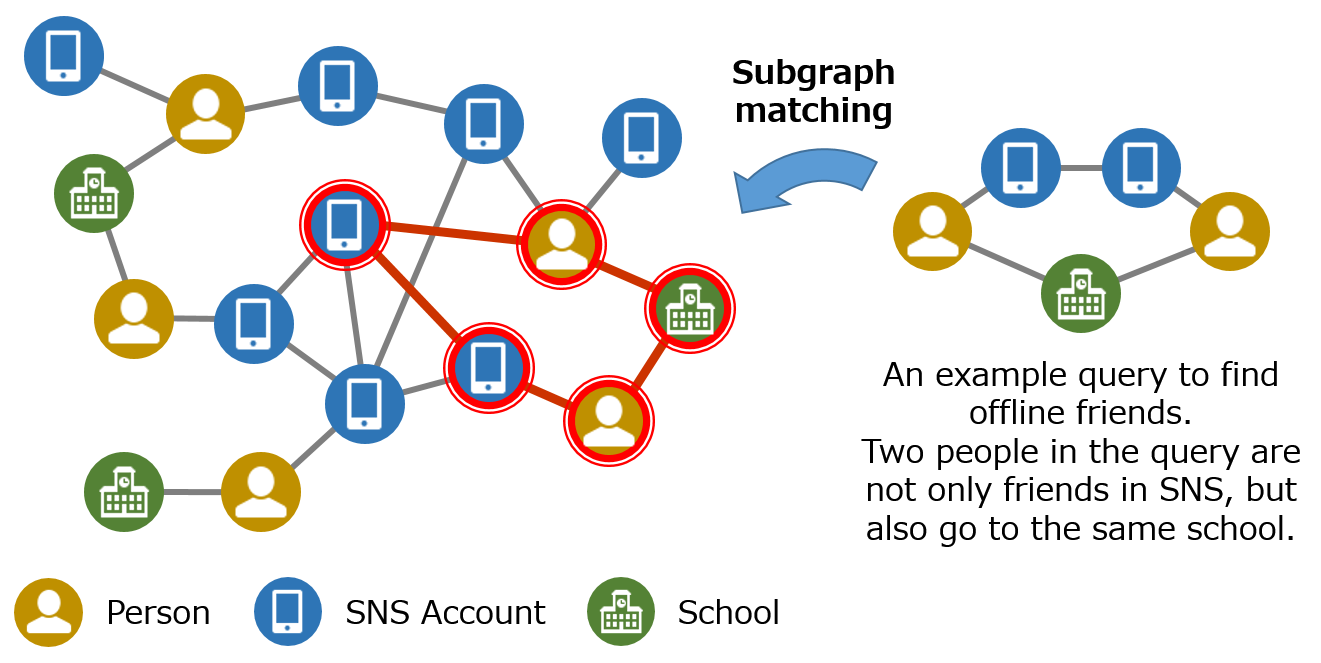
ある大きなグラフの中から特定のグラフ構造を探索する問題はサブグラフマッチングと呼ばれ,グラフから複雑な情報を引き出すために用いられています. 例えばソーシャルネットワークにおいて,SNS 上のみでなくオフラインでも友人である可能性が高い人物を発見できます. また,企業間の取引関係を表すグラフから循環取引などの会計不正を発見するような使い方も考えられます. しかしながら多くの応用がある一方で,サブグラフマッチングは処理時間が爆発的に増加しやすい問題(NP 完全問題)としても知られています. そこでビッグデータ工学講座では,効率的な探索により高速なサブグラフマッチングを可能にするアルゴリズムの確立を目指しています.
特許評価AIシステム
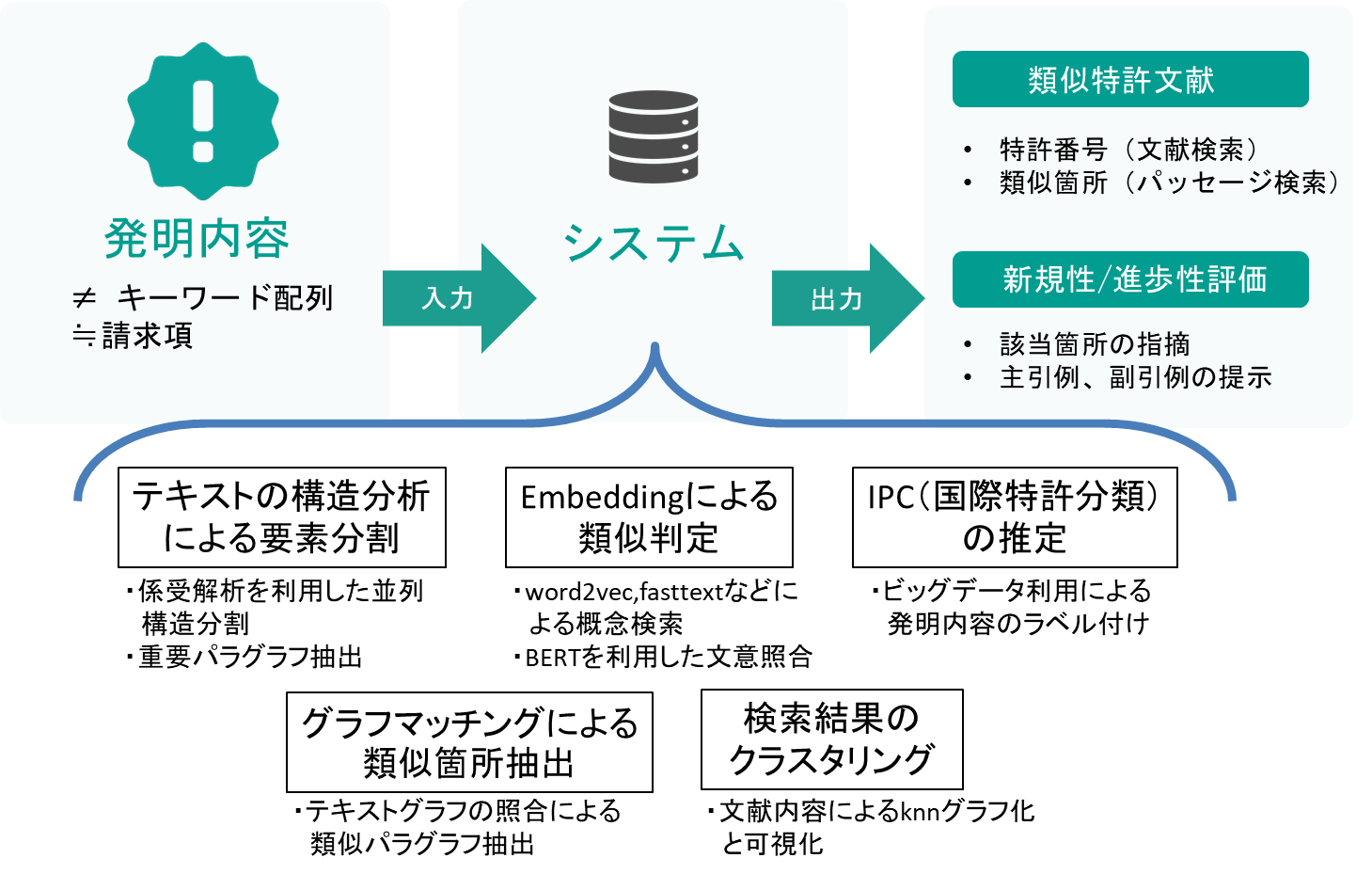
全世界での登録特許数の数は1千万件を超え,年間の特許出願数は3百万件を超える昨今,企業における特許調査の負荷は大きくなっています.また,中国における年間の特許出願数は世界トップで増加傾向であり,知財権のグローバル化も進んでいることから,ますます網羅的な調査は困難となります.このような状況から,人間による調査だけでは調査不足に陥ると予測しており,AIを利用した高速で幅広い特許調査が必要になってくると考えています.本研究では自然言語処理における近年のニューラルネットワーク等による機械学習の成果を利用し,グラフマッチングやクラスタリングなどビッグデータ分析の手法も取り入れながら,特許調査を半自動で高精度に行うシステムの開発を目指しています.
発見的データ分析
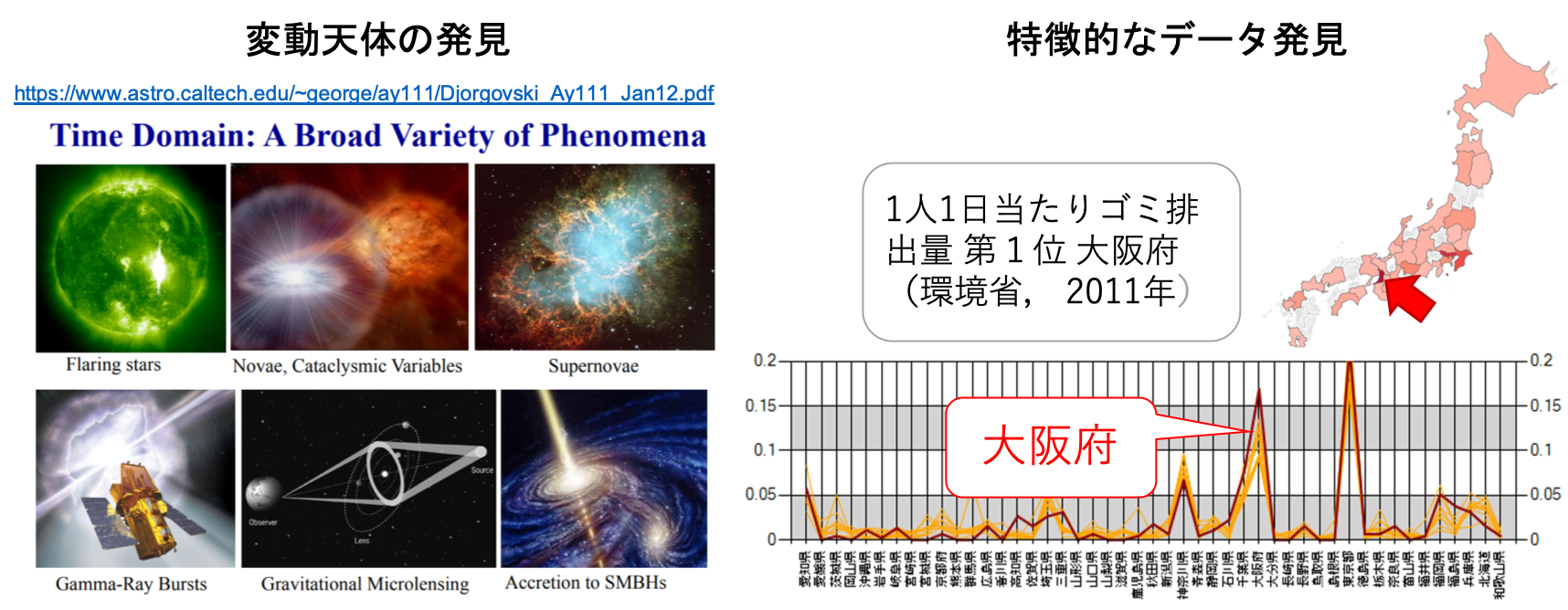
発見的データ分析とは,購買データや天体観測データなどの多様で膨大なデータを対象として,通常とは異なる特徴的なデータを発見する技術です.例えば,特定の地域や季節において他とは異なる特徴的なデータを発見して活用する例などが挙げられます.特に,国立天文台と協力して,正常パターンを学習して異常検知する技術や,欠損値補完などの技術に取り組んでおり,短期間で明るさや位置が変化する変動天体の発見を目指しています.
属性グラフクラスタリング
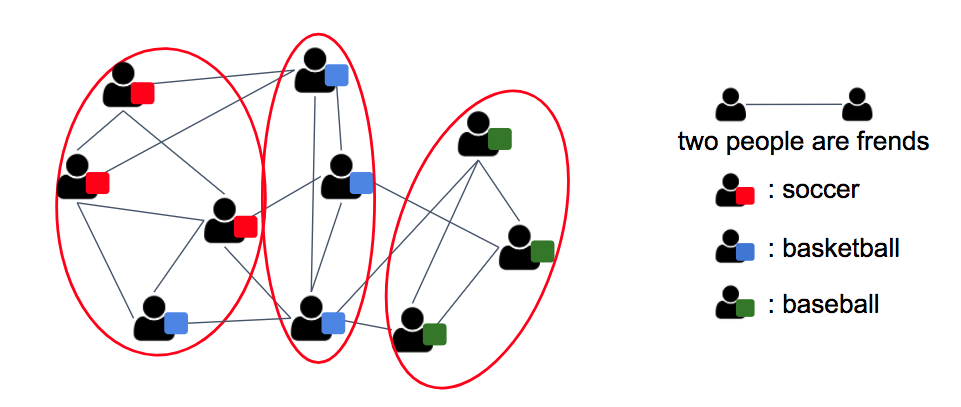
属性付きグラフとはノード間を結ぶエッジによる構造的な関係だけでなく,ノードが個々に特徴量を持つようなグラフです. 例えばSNSでのユーザをノードとすると,友達関係にあるユーザ間にエッジを設け,そのユーザの興味のあるカテゴリーなどが特徴量に当たります. 属性付きグラフクラスタリングの利点としては,従来の手法では無視されていた情報を使うことによって, より良いクラスタが抽出できると考えられることです.
経路検索
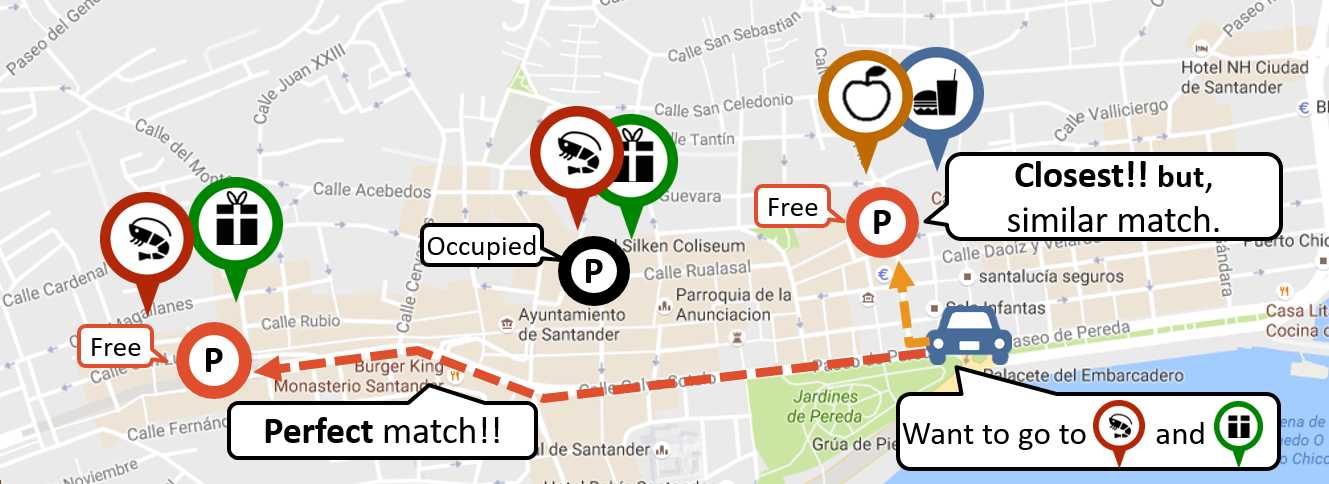
日常でも多くの方がカーナビやスマートフォンを用いて経路検索を使用しています. 既存のサービスでは検索できないような便利で新しい経路検索の考案を行っております. 特に,実際のデータがもつ属性(カテゴリや説明文等)や周辺情報に着目し, 距離だけではなく他の項目との適合による検索,駐車場情報などとの連携について取り組んでいます. 他にも,既存の検索方法の効率化や地方自治体と連携して実サービスの構築 (スペインサンタンデル市)も行っています.
時空間データマイニング
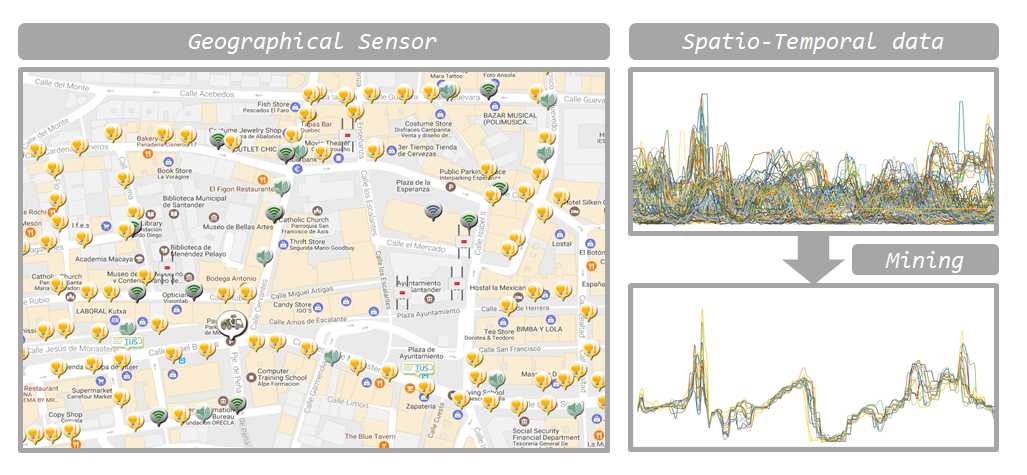
近年,街中には気温センサ,騒音センサ,交通量センサ,大気汚染物質センサなど多様なセンサが数多く設置されており, それらは毎日たくさんのデータを生み出しています. 私たちのグループはこれらのビッグデータを分析することで「気温が上昇すると交通量が増加する」, 「騒音が上昇すると大気汚染物質が増加する」といったような, 実世界で起きている事象について新たな知識を発見することを目的としています.